 |
Illustration of the local network for the proposed multi-level branched regularization framework. $B_L$ and $B_G$ denote network blocks extracted from local and global networks, respectively, and their superscripts indicate block indices. $q_L$ and $q_H$ indicate softmax outputs of the main pathway and hybrid pathways, respectively.
Solid and dashed gray lines represent forward and backpropagation flows, respectively.
For training, the standard cross-entropy losses are applied to all branches and the KL-divergence losses between the main pathway and the rest of the pathways are employed for regularization.
Note that we update the parameters in the main pathway only, which are illustrated in sky blue color in this figure.
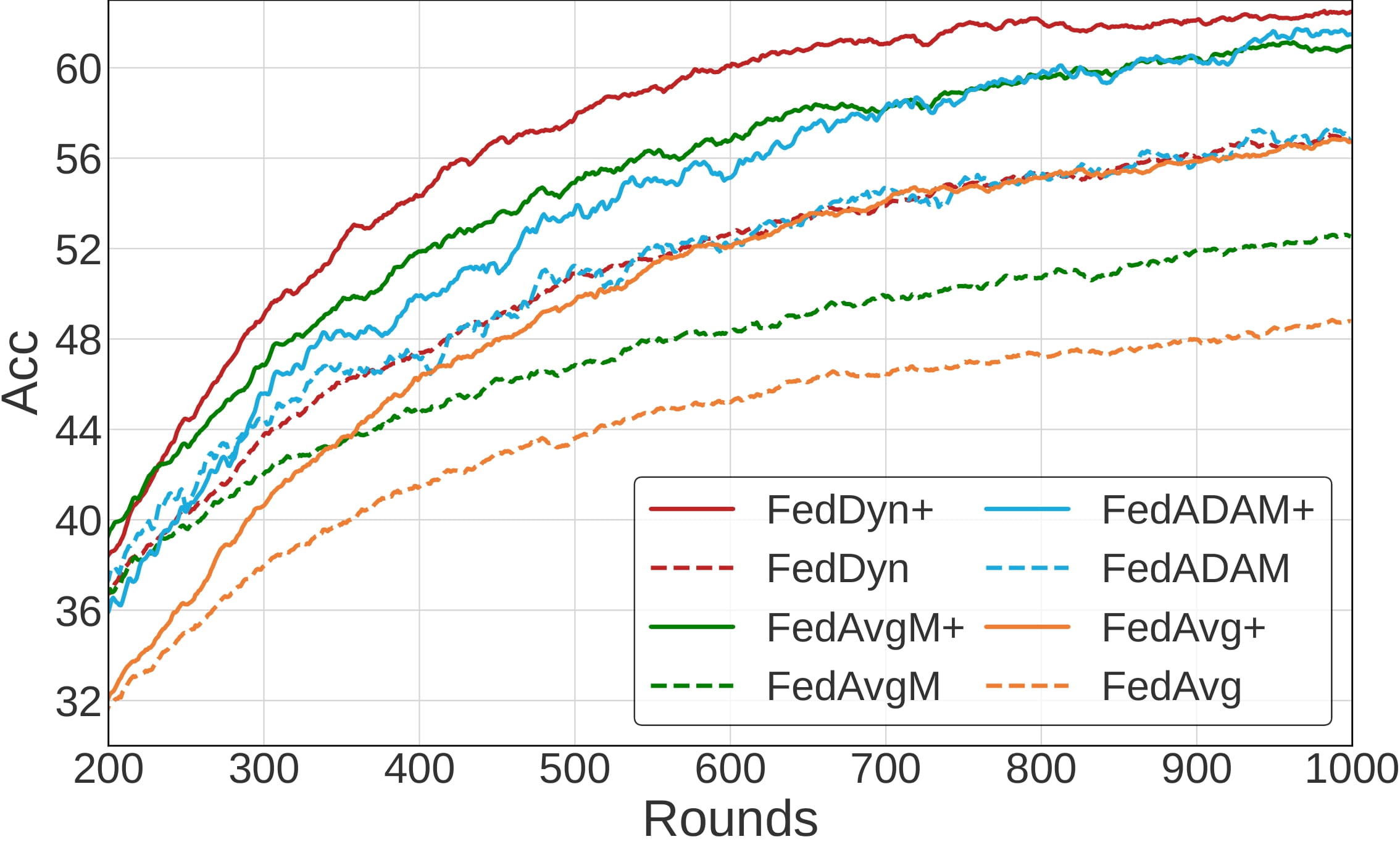
Convergence of several federated learning algorithms
 |
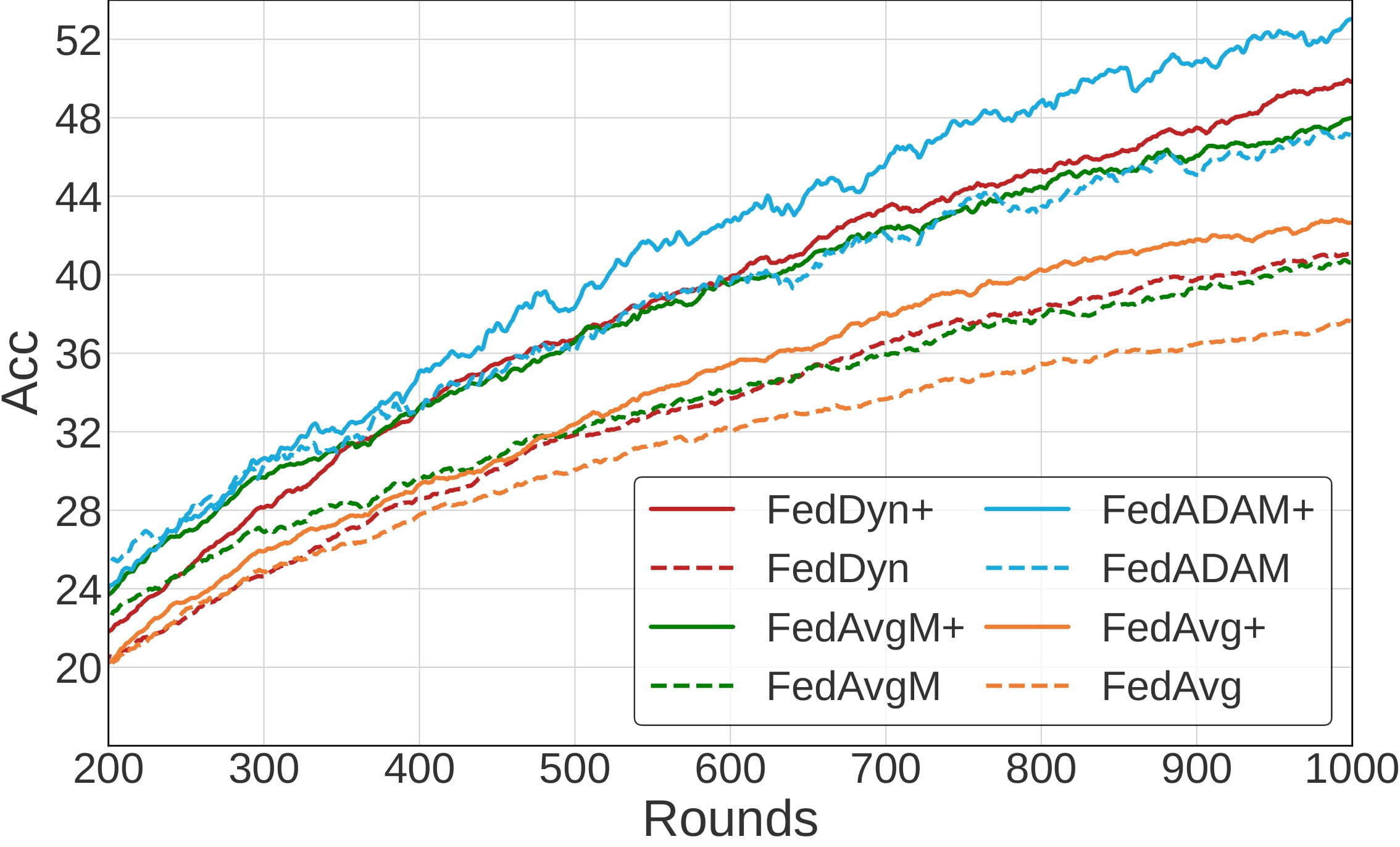 |
Dir(0.3), 5% participation, 100 clients |
Dir(0.3), 2% participation, 500 clients |
 |
 |
|
Dir(0.3), 5% participation, 100 clients |
Dir(0.3), 2% participation, 500 clients |
|
 |
 |
|
Dir(0.3), 5% participation, 100 clients |
Dir(0.3), 2% participation, 500 clients |
|
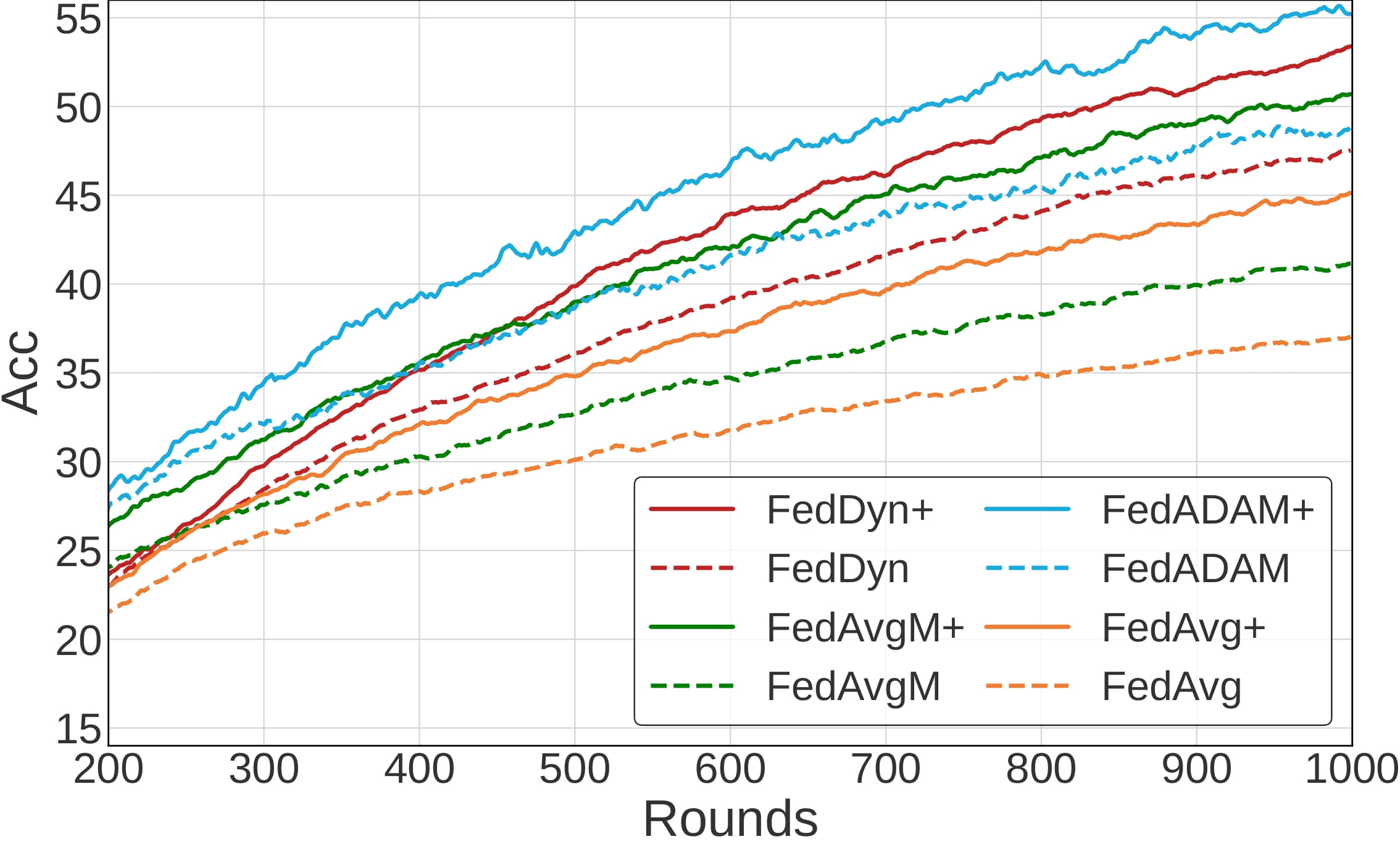
The convergence of several federated learning algorithms on CIFAR-100 in various settings. Note that + symbol indicates the incorporation of FedMLB (ours) .
The results show that FedMLB is indeed helpful for improving accuracy throughout the training procedure, facilitating convergence.
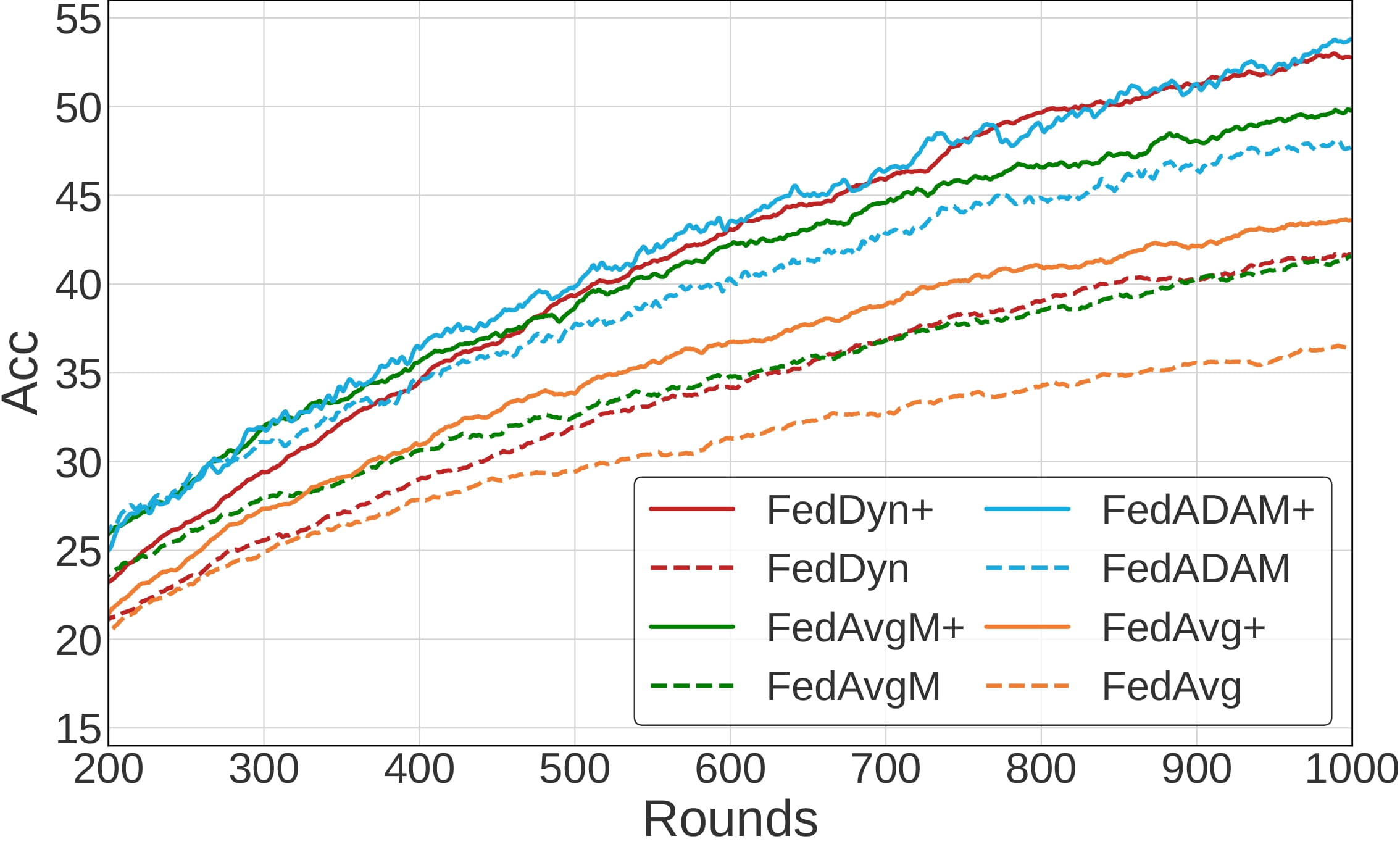
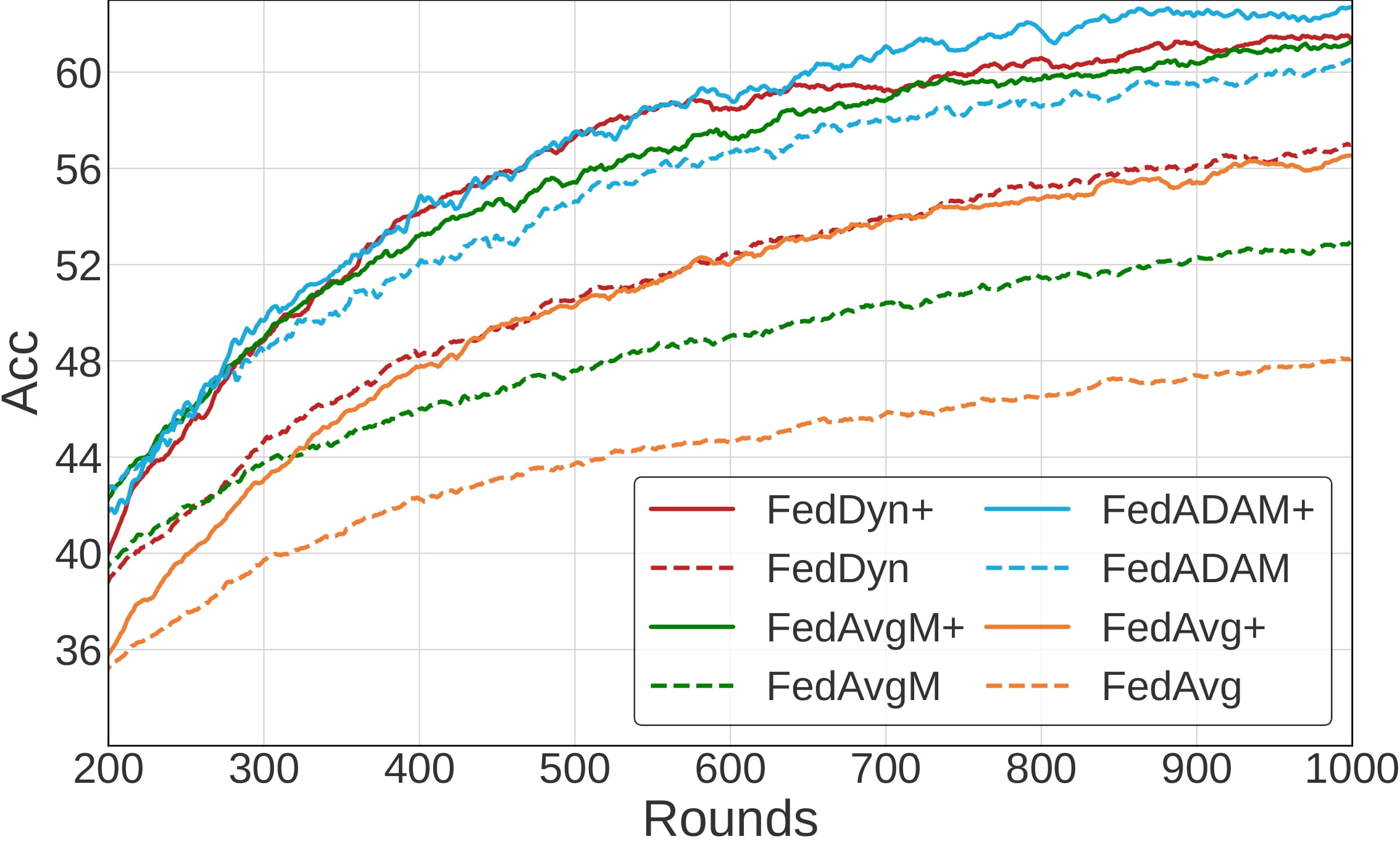
The convergence of FedMLB and other local optimization approaches
 |
 |
Dir(0.3), 5% participation, 100 clients |
Dir(0.3), 2% participation, 500 clients |
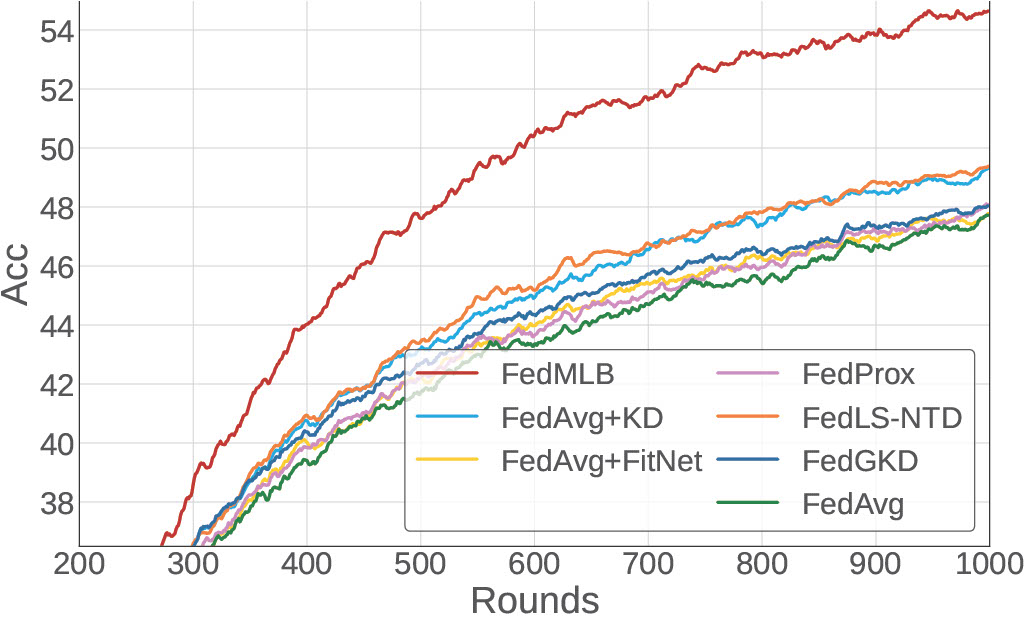
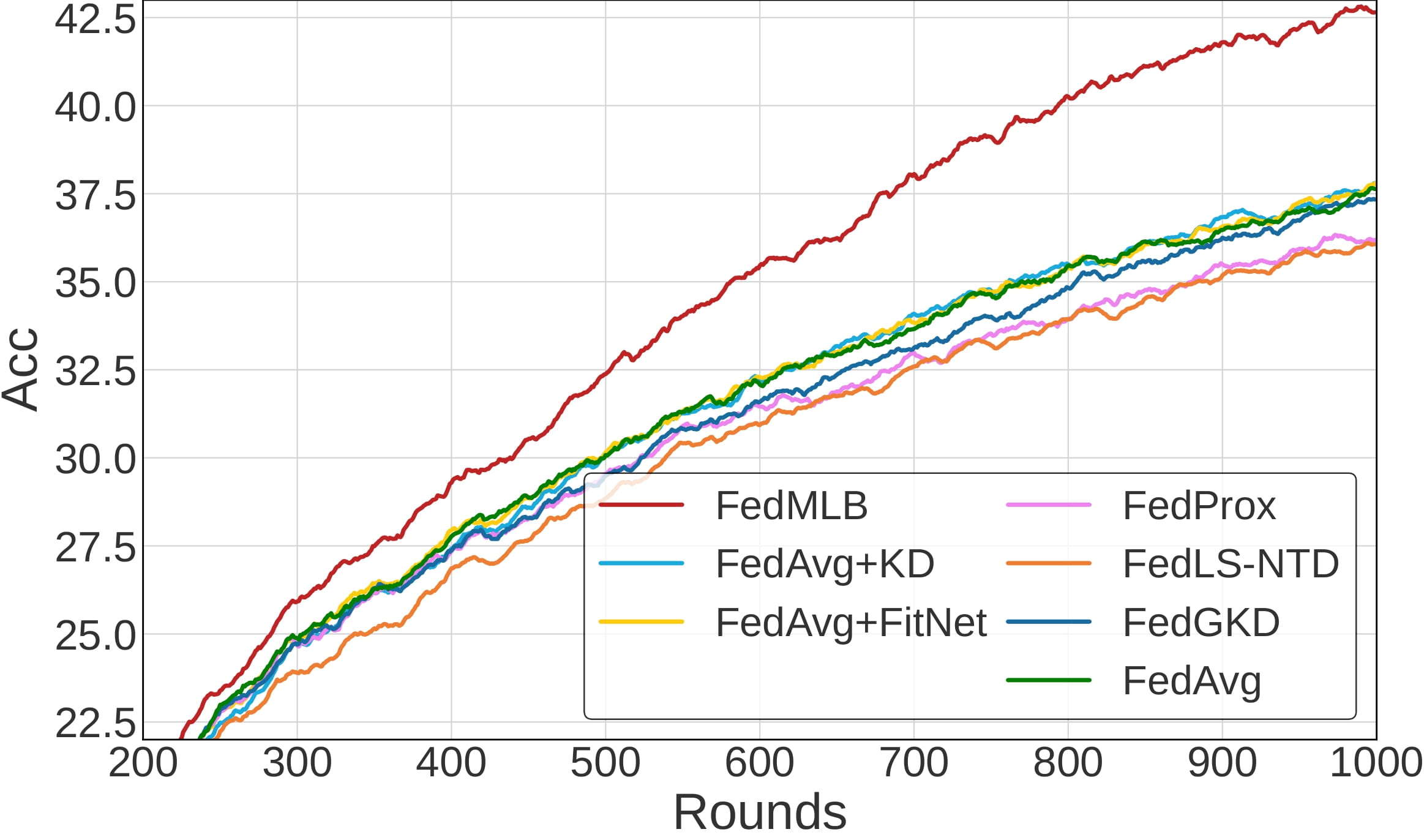
Illustrate the convergence of FedMLB in comparison to other regularization-based methods. We observe the consistent and non-trivial improvements of FedMLB over FedAvg during training while other methods only achieve marginal gains compared to FedAvg or are even worse, especially in a more challenging condition with a less participation rate.
We notice that FedMLB continuously outperforms the baselines large margins even when we increase the number of local iterations, which is effective for reducing the communication cost.
Citation
@inproceedings{kim2022multi,
author = {Kim, Jinkyu and Kim, Geeho and Han, Bohyung},
title = {Multi-Level Branched Regularization for Federated Learning},
booktitle = {ICML}
year = {2022}
}