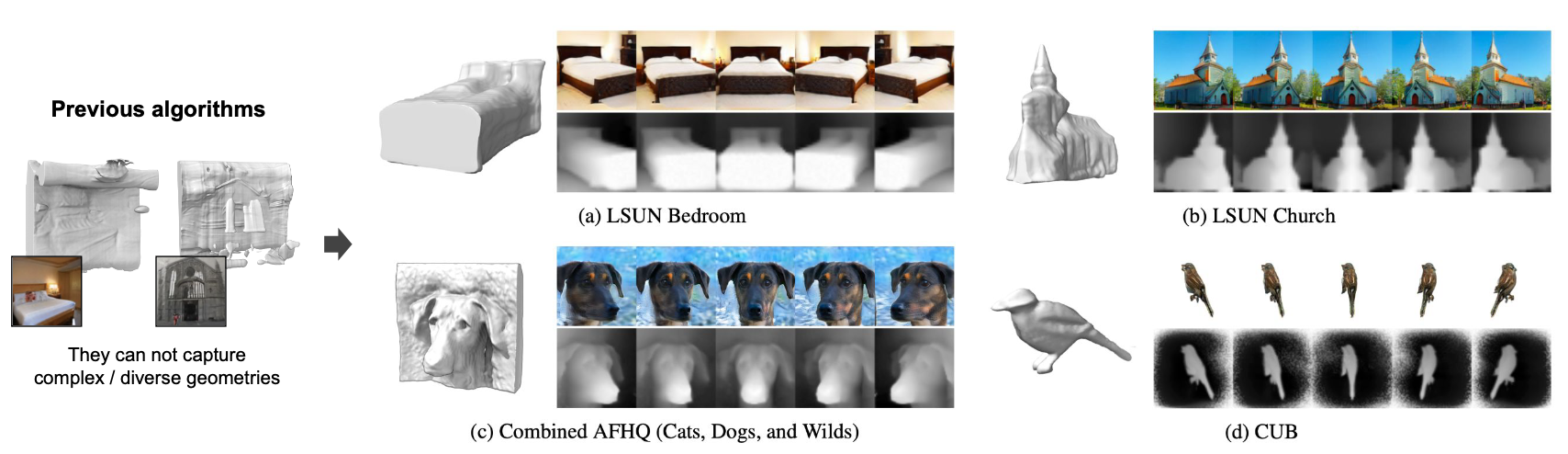
Figure 1. HyperPose learns 3D configurations from 2D image collections without camera pose labels, depth maps, or domain-specific 3D models.
01
Abstract
We propose a novel framework for training 3D-aware GANs from 2D image collections, learning both image distribution and 3D geometric configurations without strong 3D priors — no camera poses, no depth maps, no target-specific 3D models.
We introduce hyper-pose embeddings and a pose disentanglement technique that cleanly separates pose from scene information, resolving the inherent conflict between photo-realism and accurate 3D geometry.
We further propose soft contrastive learning for the continuous pose space, and a non-match loss that strengthens disentanglement.
Experiments on LSUN Bedroom, Church, AFHQ, and CUB demonstrate state-of-the-art performance, particularly for scenes with complex or diverse geometric structures.
02
Method
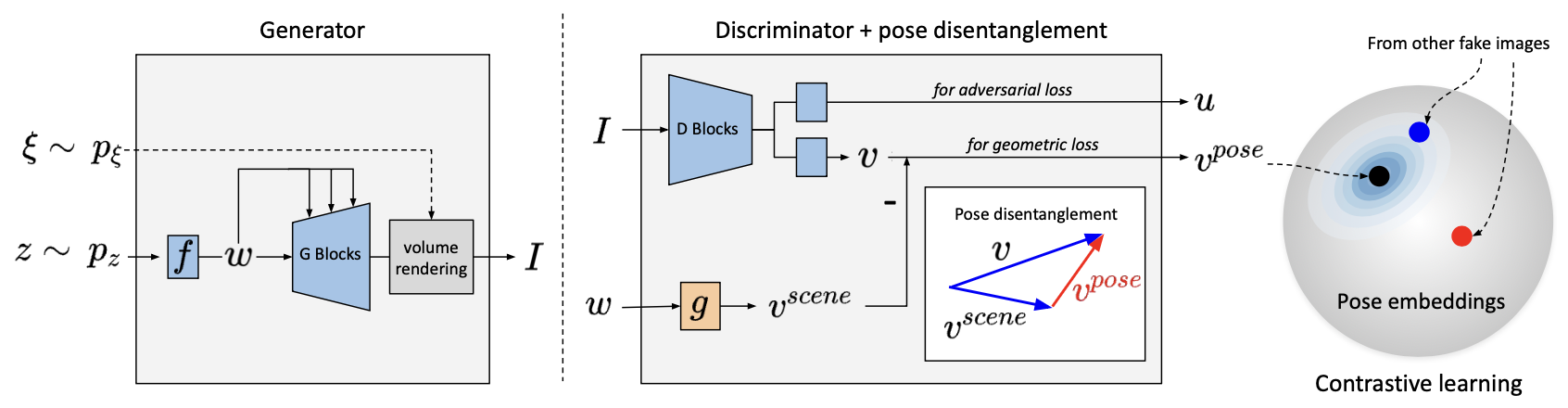
Figure 2. Overview of the HyperPose framework. All components are jointly optimised end-to-end.
1
Hyper-pose Embedding & Pose Disentanglement
Core Idea
Instead of regressing a 2D (yaw, pitch) vector, the discriminator outputs a high-dimensional embedding v ∈ ℝm.
An MLP g(·) extracts a scene embedding vscene = g(w) from the generator's latent w,
and the pure pose signal is recovered as vpose = v − vscene —
preventing pose and scene from becoming entangled.
2
Soft Contrastive Loss LSCLTraining
Camera poses live on a continuous manifold; hard binary labels cause unstable training when many similar-pose pairs exist.
We define a smooth positive mask via S(ξ₁,ξ₂) = exp(−d²/2σ²),
assigning graded similarity weights so that near-identical poses are treated as soft positives, not negatives.
3
Non-match Loss Lnon-matchRegulariser
Synthetic hard negatives are built by mis-pairing pose and scene embeddings from different images:
v̄pose = vi − vscenej≠i.
Adding these to the contrastive denominator tightens disentanglement and yields more discriminative pose representations.
03
Experimental Results
Generated Samples
Multi-view videos generated by HyperPose across four datasets.
Figure 3. HyperPose generates high-fidelity, geometrically consistent multi-view videos — without any pose supervision.
Quantitative Results
Evaluated on four challenging benchmarks. Metrics: FID ↓, Recall/Precision ↑, NFS ↑ (3D geometry), Depth FID ↓ (Bedroom only).
.
LSUN Bedroom — 128²
Method
Depth FID ↓
FID ↓
Recall ↑
NFS ↑
GRAF
97.4
70.7
0.00
19.4
π-GAN
124.1
56.3
0.11
9.7
GIRAFFE
145.6
42.8
0.02
16.9
GIRAFFE-HD
–
27.7
0.13
–
HyperPose
49.5
12.5
0.23
28.2
LSUN Church — 128²
Method
FID ↓
Recall ↑
Precision ↑
NFS ↑
GRAF
91.1
0.00
0.53
9.3
π-GAN
56.8
0.18
0.49
24.4
GIRAFFE
38.4
0.02
0.51
13.5
GIRAFFE-HD
10.3
–
–
–
HyperPose
5.8
0.37
0.60
29.9
Unified AFHQ — 256²
Method
FID ↓
Recall ↑
Precision ↑
NFS ↑
GRAF
107.0
0.00
0.35
8.5
π-GAN
48.4
0.12
0.41
21.4
GIRAFFE
31.3
0.04
0.51
14.2
GIRAFFE-HD
14.2
0.10
0.55
–
StyleNeRF
14.0
–
–
–
HyperPose
7.5
0.30
0.53
19.2
CUB — Large Pose Variation
Method
FID ↓
Recall ↑
Precision ↑
NFS ↑
GRAF
46.3
0.09
0.67
21.3
π-GAN
48.8
0.10
0.64
22.1
GIRAFFE
49.3
0.04
0.68
30.6
GIRAFFE-HD
24.3
0.17
0.67
–
HyperPose
10.8
0.39
0.62
44.5
HyperPose outperforms all baselines across every dataset and metric. The CUB gain (FID 10.8 vs. 24.3) highlights the strength of continuous pose modeling under large geometric variation.
Ablation Study
LSUN Bedroom 128². Each component is validated in isolation.
Component Contributions
Pose Disentangle.
Lnon-match
FID ↓
Precision ↑
NFS ↑
✗
✗
13.4
0.51
28.4
✓
✗
12.6
0.54
28.0
✓
✓
12.5
0.56
28.2
Pose disentanglement improves FID and Precision; Lnon-match adds further gain.
vs. Pose Regression Baseline
Method
FID ↓
Recall ↑
Depth FID ↓
w/ Lregression
12.8
0.21
138.4
HyperPose
10.8
0.23
49.5
Our contrastive approach dramatically improves 3D geometry (Depth FID 49.5 vs. 138.4).
04
BibTeX
@inproceedings{kim2026hyperpose,author={Kim, Mijeong and Kim, Namgi and Han, Bohyung},title={HyperPose: Hyper-pose Embeddings for 3D-Aware Generative Models with Self-Supervised Disentangling of Pose and Scene},booktitle={WACV},year={2026}}